This is a presentation from Code Camp 2026 in Wellington. The video is re-recorded because I forgot to press “record”…
Hi, I’m Ingo. I’m the Head of Engineering at Runn, a B2B SaaS startup doing people and project management out of Wellington, and globally distributed.

I like running, which is very on-brand for my job. I occasionally still get to code. And I’m a kid of the ’80s. I grew up with Blade Runner, Hackers, and David Hasselhoff talking to his watch to call his car, which, honestly, is not that far off the world we live in now.
Lots of things are happening at the moment. Some of them are exciting. So I thought I’d do a slightly experimental, slightly fun talk about what’s possible with AI coding.
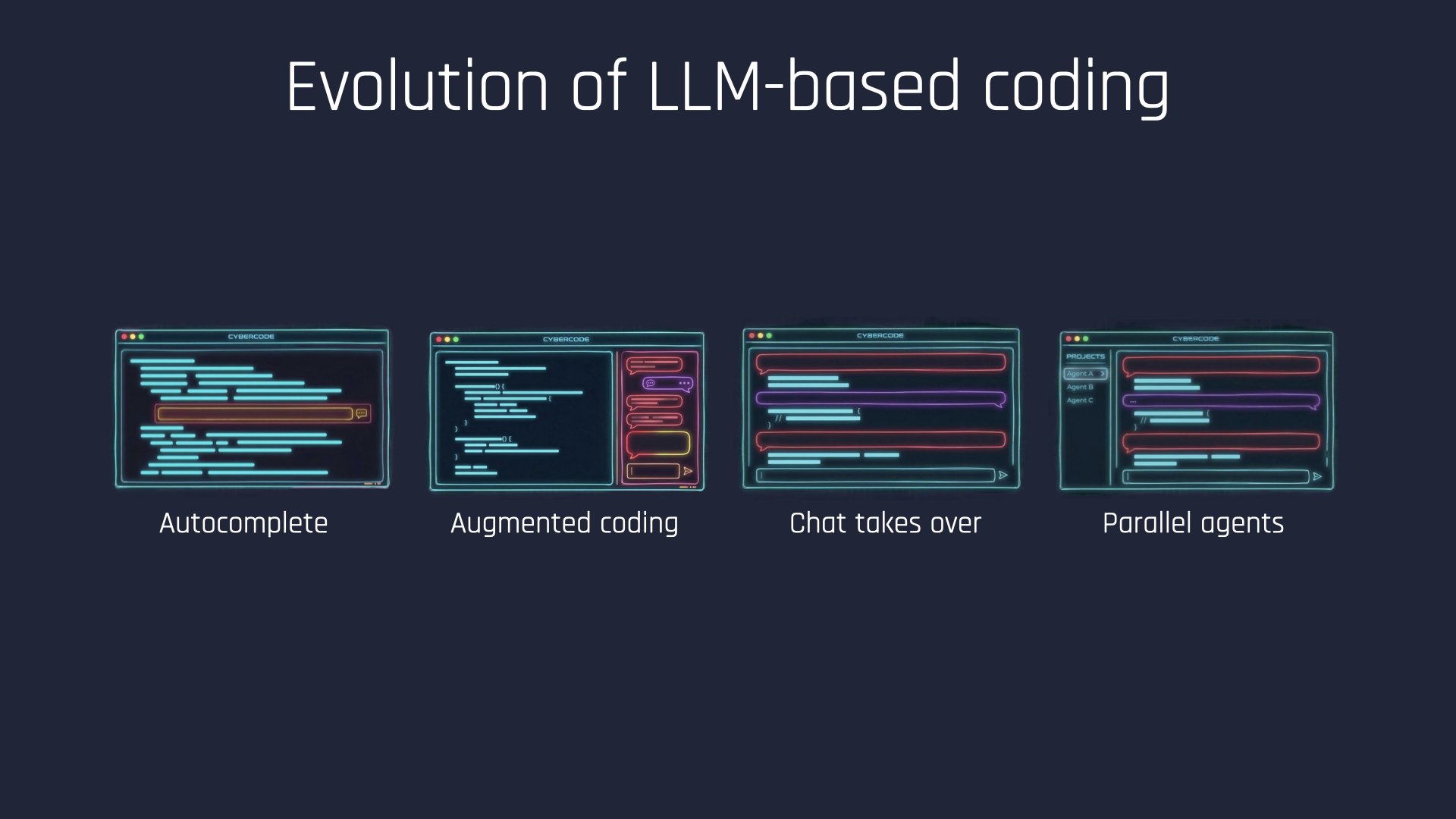
If you look at the last two and a bit years, we started by calling this stuff fancy autocomplete and mostly dismissing it. Lots of code on the screen, and a little helper on the side.
Then we moved into augmented coding: chatting to these agents and having them generate larger chunks of code for us. Then came the more chat-centric world, probably half a year to a year ago, where the code moved a bit more into the background. And where we are now is that agents have enough autonomy that you can hand them long-running tasks, and you’re often orchestrating multiple things in parallel.
That’s the current state of play.

Here’s a quote from Steve Yegge that stuck with me: coding is shifting from writing code to having conversations about it. I don’t think that’s particularly controversial anymore. He’s also the creator of Gastown. If you don’t know what that is, consider yourself lucky. Just know that he’s a bit of a mad scientist in the AI space.
The kicker is that he said this in October 2024, which was five months before Claude Code was even in preview mode. So that’s a guy living on the edge, for better or worse.

Then, in a podcast I listened to a few weeks ago, he said that by the end of this year, most people will be programming by talking to a face.
I don’t know about you, but I find the “talking to a face” bit a little hard to imagine. But the talking part made me wonder: how far can you actually take this?

Voice is already very feasible. It has genuinely changed how I interact with these systems. And it’s about much more than typing faster.
It’s really about interacting with agents at a higher level. You’re trusting the transcription, which is what makes you fast, but you also simply can’t dictate file paths, line references, or bits of code all day and expect that to be a good experience. Voice pushes you upward into intent, not implementation.
Which also means you’re giving the agent more trust and more autonomy.

So what’s next? You can already code on your phone. Claude Code just released Remote Control, so you can leave your laptop at home — or in the office — while you go out for a walk and chat with the agent while it works away on your machine.
You can do this with voice input already. But I wanted to take it one step further and have the machine talk back to me, without looking at the screen at all. Leave the phone in the pocket and go out for a run.

I’d tried something like this before with a very early-stage open source project called Happier. That pre-release warning is definitely warranted. Voice in and voice out are among its more experimental features.
It’s trying to be a more remote coding tool: an abstraction layer on top of all these coding agents. It’s also been a fascinating project to watch. More or less one contributor, doing something like 2,000 commits a month, very AI-forward. I’m about two dozen commits into my own fork just to get this thing working the way I wanted.
So, yes, it’s been a bit of a journey.
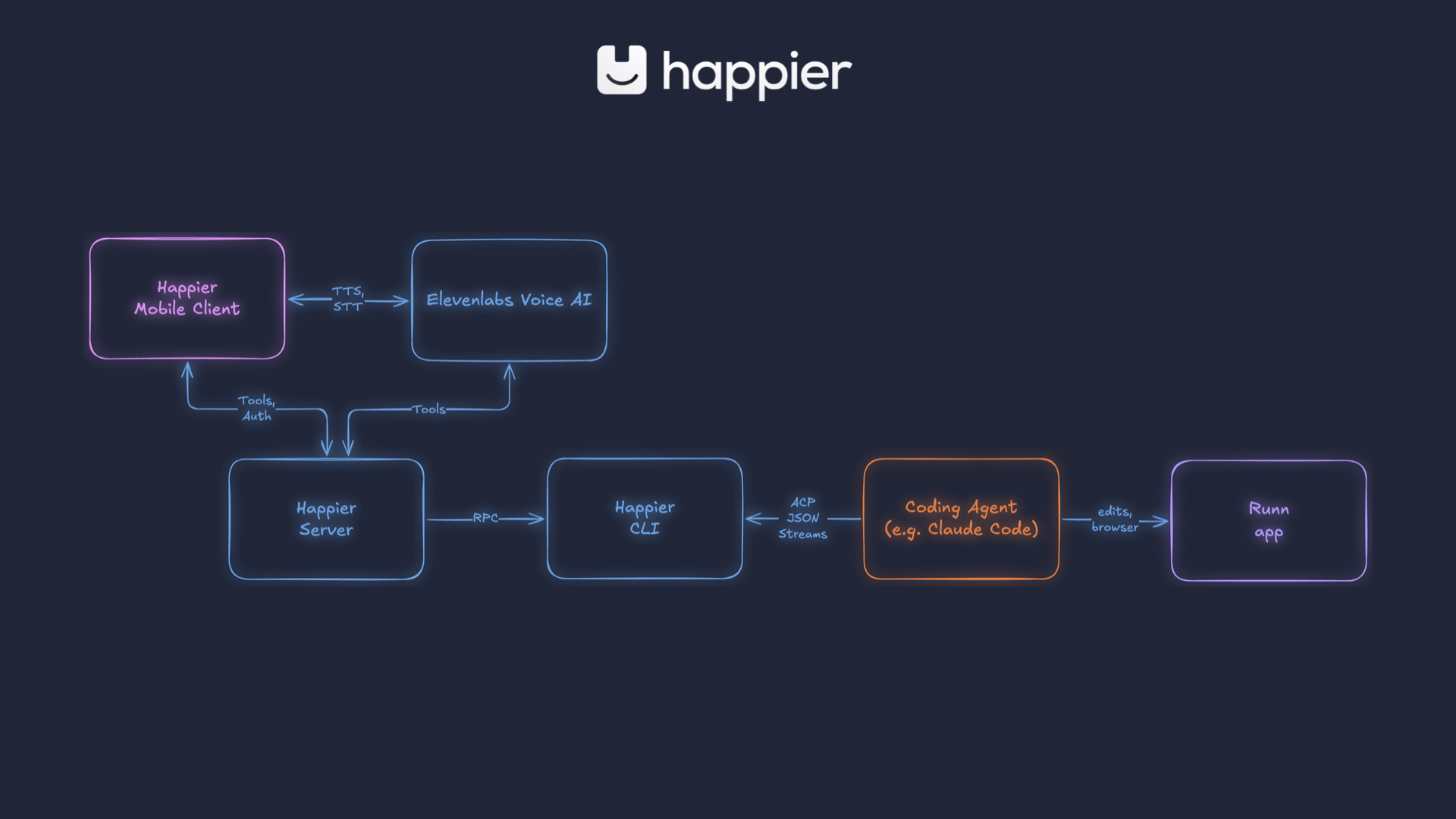
Very briefly, this is how it hangs together. I’m using the Happier mobile client. That talks to a self-hosted server running on my laptop, which talks to a CLI, which talks to a coding agent — where the real work actually happens.
That, in turn, is wired into a local development copy of the Runn app. And what I’m really interacting with is the ElevenLabs voice agent. That handles text-to-speech and speech-to-text, but it also has tools it can call on the Happier server, so it becomes an alternate pathway for the same instructions.
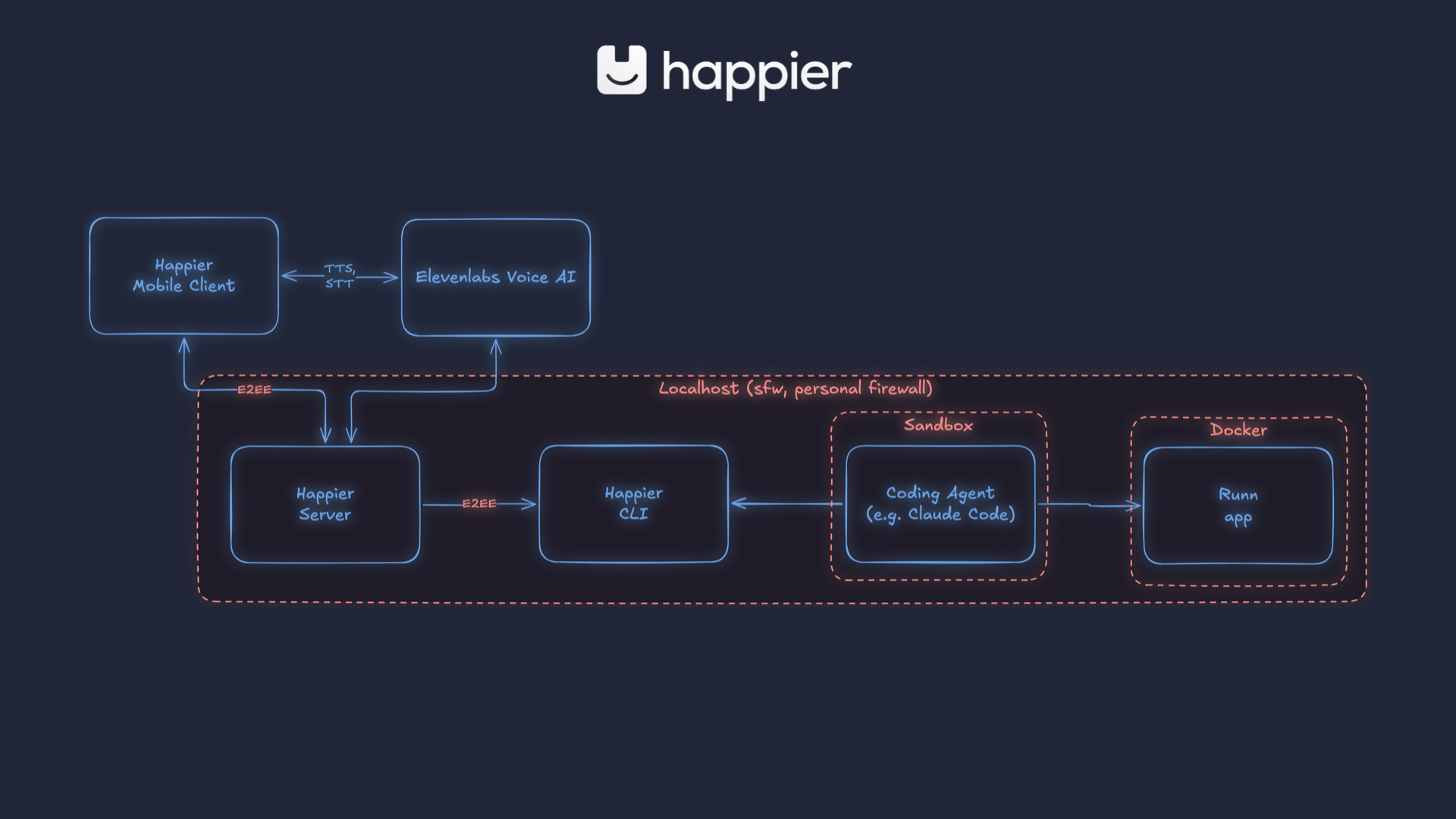
A quick word on security, because that’s understandably front of mind in the current AI world. This was all running locally, self-hosted. Happier is end-to-end encrypted by design, so the server itself doesn’t actually know what is flowing through it.
The Runn application is running in Docker with some limitations, but the really important bit is that I’m using Claude Code in sandbox mode. A lot of the preparation work here was about getting the flow smooth enough inside a sandbox where the agent doesn’t constantly stop to ask for permissions.
Because when voice is your only interface, friction matters. You probably don’t want it reading out every bash command it wants to run and waiting for manual approval. So there is definitely a certain amount of vibe coding here — along with trust, guardrails, and restricted control inside the sandbox.
For the demo, I picked a bug in a fairly small part of the app. In Runn, you can manage skills and set skill levels. And when you unset them, things blow up.
Not the hardest bug in the world to identify, but that wasn’t really the point. This was a proof of concept.
So I showed a two-and-a-half-minute video of how this went. I asked the agent to log into the app and navigate to the Manage section. On the right side of the screen you can see the actual Claude Code responses; what I’m hearing is a paraphrased version coming from the voice agent.
And yes, I do recognize the irony of promoting this as “hands-free” while using not one but two phones to record this part of the talk, and running around like an idiot with both of them in my hands.
The agent-browser is using a browser layer built on top of Playwright to log into the app and effectively be my eyes. It navigates through the app autonomously, working off representations of the accessibility tree — what a button is, where it leads, what it can see — while I guide it toward the right part of the interface.
I got it to reproduce the bug by setting and unsetting a skill level. That part actually worked. The interesting bit came next: Claude Code had already reproduced the bug, understood the root cause, and wanted me to make a choice about how to fix it — but the voice layer didn’t surface that to me because I wasn’t looking at the screen.
So I asked, “Alright, what’s the bug?” and the voice agent basically gaslit me by saying it was still checking and would update me shortly. It eventually got there. It fixed the bug. But this may have been the first time I’ve been gaslit in the opposite direction: the machine had already done the work and was pretending it hadn’t.

Takeaways
First, mediating between two agents is confusing. That was an architectural choice in the tool, not necessarily the only way to build this, but it was definitely confusing in practice. I tried to prompt-engineer my way out of it — telling it that it is Claude Code, not a separate entity, and that it should ask for permissions in a certain way — and it’s hard. I do not envy anyone building voice agents at scale.
Second, harness engineering is a powerful multiplier. I probably spent more time on the browser skill and smoothing the login and navigation path within the Runn app. A lot of this work is really about removing blockers for the agents.
Third, agents work better with accessible interfaces. Browser agents get faster and more reliable when your app is well-labeled and structured. That means fewer screenshots, fewer wasted tokens, and less clicking around in the dark. Accessibility is obviously important for humans, but it turns out it’s also just an efficient way to build software in the age of agents.
Fourth, micro-managing AI is absolutely a thing. I could have given Claude Code the problem and walked away. Instead, I found myself saying, “Go to the skills section. Have you done it yet?” and generally behaving like an unnecessary middle manager. At times I felt like the fifth wheel in the conversation.
And finally, humans are still on the hook for what runs in prod. Even if the system could commit, push, and merge, I wouldn’t tell it to. We still own the code. We still need to understand it. This is a way to get code written, not a way to stop being responsible for it.

My conclusion is that voice coding is still a bottleneck — especially if you’re relying on voice both ways and not looking at the screen.
And honestly, let’s hope it stays that way. Because if we ever get to the point where you no longer need to verify anything on-screen or at a code level, that probably means you trust the agent enough that your job as a programmer is becoming a lot less necessary.
I also realized, while doing this, that I do running and coding for very different reasons. And I’m not especially keen to combine those two things again any time soon!